

Build Search and RAG Systems on PostgreSQL Using Cohere and Pgai

Enterprise-ready LLMs from Cohere—now available in the pgai PostgreSQL extension.
Cohere is a leading generative AI company in the field of large language models (LLMs) and retrieval-augmented generation (RAG) systems. What sets Cohere apart from other model developers is its unwavering focus on enterprise needs and support for multiple languages.
Cohere models
Cohere has quickly gained traction among businesses and developers alike, thanks to its suite of models that cater to key steps of the AI application-building process: text embedding, result reranking, and reasoning. Here’s an overview of Cohere models:
- Cohere Embed: A leading text representation model supporting over 100 languages, with the latest version (Embed v3) capable of evaluating document quality and relevance to queries. Cohere Embed is ideal for semantic search, retrieval-augmented generation (RAG), clustering, and classification tasks.
- Cohere Rerank: A model that significantly improves search quality for any keyword or vector search system with minimal code changes. It’s optimized for high throughput and reduced compute requirements while leveraging Cohere's embedding performance for accurate reranking. Cohere rerank is system agnostic, meaning it can be used with any vector search system, including PostgreSQL.
- Cohere Command: A family of highly scalable language models optimized for enterprise use. Command supports RAG, multi-language use, tool use, and citations. Command R+ is the most advanced model, as it’s optimized for conversational interaction and long-context tasks. Command R is well suited for simpler RAG and single-step tool use tasks and is the most cost-effective choice out of the Command family.
What is pgai?
Pgai is an open-source PostgreSQL extension that brings AI models closer to your data, simplifying tasks such as embedding creation, text classification, semantic search, and retrieval-augmented generation on data stored in PostgreSQL.
Pgai supports the entire suite of Cohere Embed, Rerank, and Command models. This means that developers can now:
- Create embeddings using Cohere’s Embed model for data inside PostgreSQL tables, all without having pipe data out and back into the database.
- Build hybrid search systems for higher quality results in search and RAG applications using Cohere Rerank, combining vector search in pgvector and PostgreSQL full-text search.
- Perform tasks like classification, summarization, data enrichment, and other reasoning tasks on data in PostgreSQL tables using Cohere Command models.
- Build highly accurate RAG systems completely in SQL, leveraging the Cohere Embed, Rerank, and Command models altogether.
We built pgai to give more PostgreSQL developers AI Engineering superpowers. Pgai makes it easier for database developers familiar with PostgreSQL to become "AI engineers" by providing familiar SQL-based interfaces to AI functionalities like embedding, creating, and model usage.
While Command is the flagship model for building scalable, production-ready AI applications, pgai supports a variety of models in the Cohere lineup. This includes specialized embedding models that support over 100 languages, enabling developers to select the most suitable model for their specific enterprise use case.
Whether it's building internal AI knowledge assistants, security documentation AI, customer feedback analysis, or employee support systems, Cohere's models integrated with pgai and PostgreSQL offer powerful solutions.
Getting started with Cohere models in pgai
Ready to start building with Cohere's suite of powerful language models and PostgreSQL? Pgai is open source under the PostgreSQL License and is available for immediate use in your AI projects. You can find installation instructions on the pgai GitHub repository. You can also access pgai (alongside pgvector and pgvectorscale) on any database service on Timescale’s Cloud PostgreSQL platform. If you’re new to Timescale, you can get started with a free cloud PostgreSQL database here.
Once connected to your database, create the pgai extension by running:
Join the Postgres AI Community
Have questions about using Cohere models with pgai? Join the Postgres for AI Discord, where you can share your projects, seek help, and collaborate with a community of peers. You can also open an issue on the pgai GitHub (and while you’re there, stars are always appreciated ⭐).
Next, let's explore the benefits of using Cohere models for building enterprise AI applications. And we’ll close with a real-world example of using Cohere models to build a hybrid search system, combining pgvector semantic search with PostgreSQL full-text search.
Let's dive in...
Why Use Cohere Models for RAG and Search Applications?
Cohere's suite of models offers several advantages for enterprise-grade RAG and search applications:
High-quality results: Cohere models excel in understanding business language, providing relevant content, and tackling complex enterprise challenges.
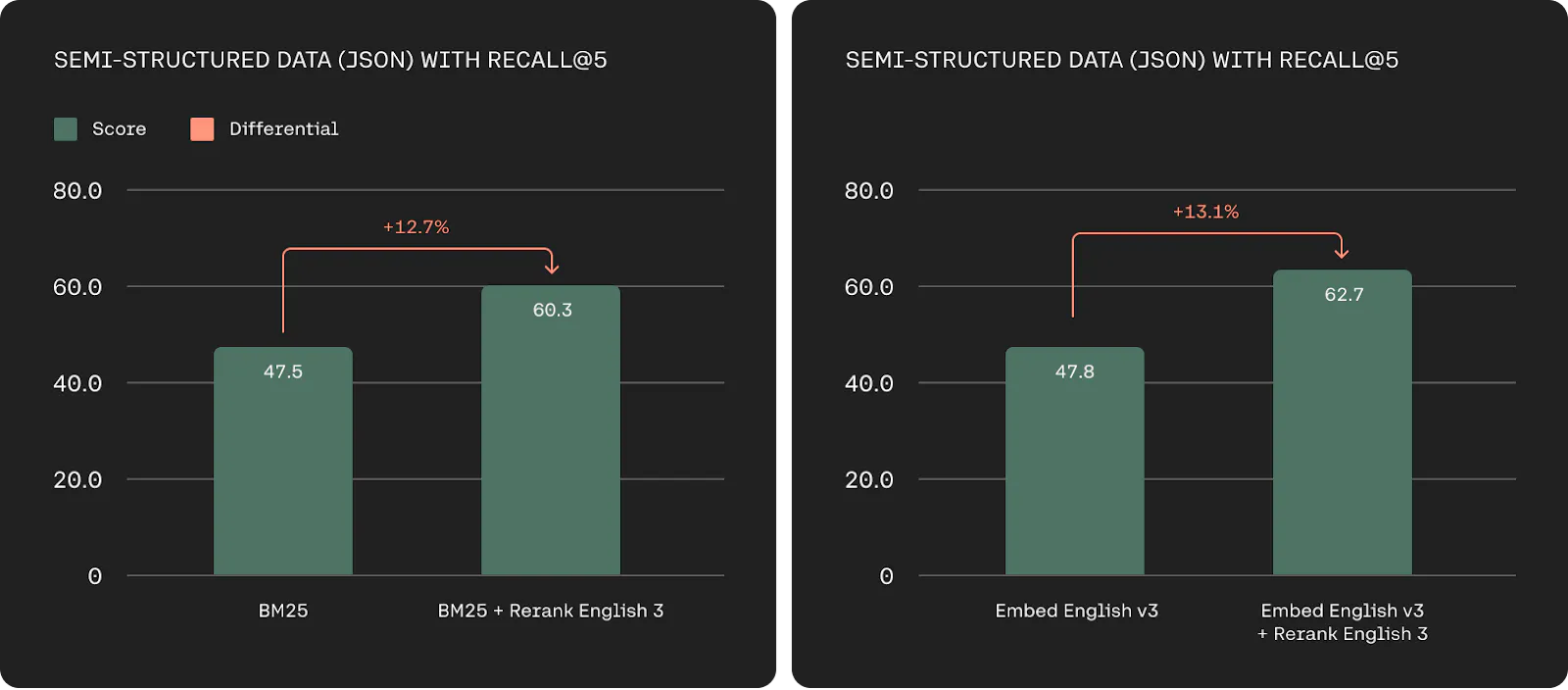
Multi-language support: With support for over 100 languages, Cohere models are ideal for global enterprises. For example, Command R+ is optimized to perform well in the following languages: English, French, Spanish, Italian, German, Brazilian Portuguese, Japanese, Korean, Simplified Chinese, and Arabic. Additionally, pre-training data has been included for the following 13 languages: Russian, Polish, Turkish, Vietnamese, Dutch, Czech, Indonesian, Ukrainian, Romanian, Greek, Hindi, Hebrew, and Persian.
Flexible deployment: Cohere’s flexible deployment options allow businesses to bring Cohere's models to their own data, either on their servers or in private/commercial clouds, addressing critical security and compliance concerns. This flexibility, combined with Cohere's robust API and partnerships with major cloud providers like Amazon Web Services (through the Bedrock AI platform), ensures seamless integration and improved scalability for enterprise applications.
Enterprise focus: Strategic partnerships with industry leaders like Fujitsu, Oracle, and McKinsey & Company underscore Cohere's enterprise-centric approach.
Cohere models enable sophisticated enterprise AI applications such as:
- Investment research assistants
- Support chatbots and Intelligent support copilots
- Executive AI assistants
- Document summarization tools
- Knowledge and project staffing assistants
- Regulatory compliance monitoring
- Sentiment analysis for brand management
- Research and development assistance
Cohere's models offer a powerful, scalable, and easily implementable solution for enterprise search and RAG applications, balancing high accuracy with efficient performance.
Tutorial: Build Search and RAG Systems on PostgreSQL Using Cohere and Pgai
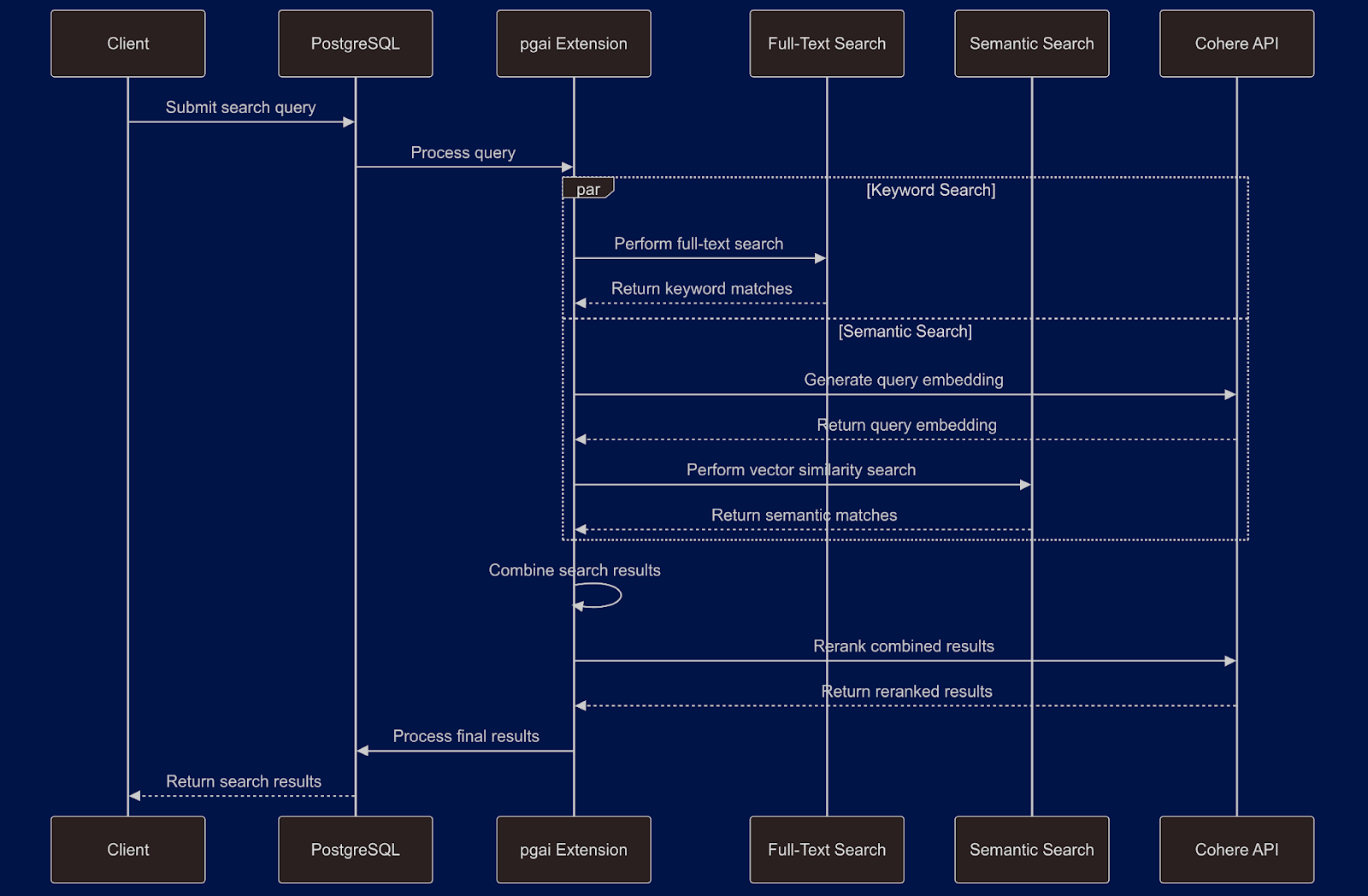
Let’s look at an example of why Cohere's support in pgai is such a game-changer. We’ll perform a hybrid search over a corpus of news articles, combining PostgreSQL full-text search with pgvector’s semantic search, leveraging Cohere Embed and Rerank models in the process.
Here's what we'll cover:
- Setting up your environment: Creating a Python virtual environment, installing necessary libraries, and setting up a PostgreSQL database with the pgai extension.
- Preparing your data: Creating a table to store news articles and loading sample data from the CNN/Daily Mail news dataset.
- Generating vector embeddings using pgai: Using Cohere's Embed model to create vector representations of text.
- Implementing full text and semantic search capabilities: Setting up PostgreSQL's full-text search for keyword matching and creating a vector search index for semantic search.
- Performing searches: Executing keyword searches using PostgreSQL's full-text search and semantic searches on embeddings using pgvector HNSW.
- Performing hybrid search: Combining keyword and semantic search results by using Cohere's Rerank model to improve result relevance.
By the end of this tutorial, you'll have a powerful hybrid search system that provides highly relevant search results, leveraging both traditional keyword search and semantic search techniques.
Setting up your environment
To begin, we'll set up a Python virtual environment and install the necessary libraries. This ensures a clean, isolated environment for our project.
This setup:
- Creates a new directory for our project
- Sets up a Python virtual environment
- Activates the virtual environment
- Installs the required Python packages:
datasets: For loading our sample datasetpsycopg: PostgreSQL adapter for Pythonpython-dotenv: For managing environment variables
Next, create a .env file in your project directory to store your database connection string and Cohere API key:
Replace the placeholders with your actual database credentials and Cohere API key.
Setting up your PostgreSQL database
Now, let's set up our PostgreSQL database with the necessary extensions and table structure. We’ll create a table to hold our news articles. The embedding column will hold our embeddings which we’ll create using the Cohere Embed model. The tsv column will hold our full-text-search vectors.
Connect to your PostgreSQL database and run the following SQL commands:
This SQL script:
- Creates the
pgaiextension - Sets up a table to store our news articles, including columns for the article text, embeddings, and a full-text search vector
- Creates an index on the full-text search vector for efficient keyword searches
Load the dataset
Now that our database is set up, we'll load sample data from the CNN/Daily Mail dataset. We'll use Python to download the dataset and efficiently insert it into our PostgreSQL table using the copy command with the binary format.
Create a new file called load_data.py in your project directory and add the following code:
This script:
- Loads environment variables from the .env file
- Downloads the CNN/Daily Mail dataset
- Selects a random subset of 1,000 articles from the test set
- Efficiently inserts the data into our PostgreSQL table using the binary COPY command
To run the script and load the data:
This approach is much faster than inserting rows one by one, especially for larger datasets. After running the script, you should have 1000 news articles loaded into your cnn_daily_mail table, ready for the next steps in our tutorial.
Note: Before running this script, make sure your .env file is properly set up with the correct database URL.
Create vector embeddings with Cohere Embed and pgai
In this step, we'll use Cohere's Embed model to generate vector embeddings for our news articles. These embeddings will enable semantic search capabilities.
First, set your Cohere API key in your PostgreSQL session:
The pgai extension will use this key by default for the duration of your database session.
We'll explore two methods to generate embeddings: a simple approach and a more production-ready solution. Choose method 1 if you’re just experimenting and method 2 if you want to see how you’d run this in production.
Method 1: Easy mode (for small datasets)
This is the "easy-mode" approach to generating embeddings for each news article.
This method is straightforward but can be slow for large datasets. The downside to this is that each call to Cohere is relatively slow. This makes the whole statement long-running.
Method 2: Production mode (recommended for larger datasets)
This method processes rows one at a time, allowing for better concurrency and error handling. We select and lock only a single row at a time, and we commit our work as we go along.
Note that both methods above use the cohere_embed() function provided by the pgai extension to generate embeddings for each article in the cnn_daily_mail table using the Cohere Embed v3 embedding model.
After running one of the above methods, verify that all rows have embeddings:
Create a vector search index
To optimize vector similarity searches, create an index on the embedding column:
This index uses the pgvector HNSW (hierarchical navigable small world) algorithm, which is efficient for nearest-neighbor searches in high-dimensional spaces.
With these steps completed, your database is now set up for both keyword-based and semantic searches. In the next section, we'll explore how to perform these searches using pgai and Cohere's models.
Perform a Keyword Search in PostgreSQL
PostgreSQL's full-text search capabilities allow us to perform complex keyword searches efficiently. We'll use the tsv column we created earlier, which contains the tsvector representation of each article.
Let's break down this query:
@@is the text search match operator in PostgreSQL.to_tsquery('english', '...')converts our search terms into a tsquery type.- The search logic is: (death OR kill) AND police AND car AND dog.
This query will return articles that contain:
- Either "death" or "kill" (or their variations)
- AND "police" (or variations)
- AND "car" (or variations)
- AND "dog" (or variations)
This method of searching is fast and efficient, especially for exact keyword matches inside the article text. However, it doesn't capture semantic meaning or handle synonyms well. In the next section, we'll explore how to perform semantic searches using the embeddings we created earlier.
Perform a Semantic Search in PostgreSQL With pgvector, pgai, and Cohere Embed
Semantic search allows us to find relevant articles based on the meaning of a query rather than just matching keywords. We'll use Cohere's Embed model to convert our search query into a vector embedding, then find the most similar article embeddings using pgvector.
Let's break this query down:
- We use a CTE (Common Table Expression) named
qto generate the embedding for our search query using Cohere's model (also namedq). cohere_embed()is a function provided by pgai that interfaces with Cohere's API to create embeddings. See more in the pgai docs.- We specify
_input_type => 'search_query'to optimize the embedding for search queries. - In the main query, we order the results by the cosine distance (
<=>) between each article's embedding and our query embedding. - The
LIMIT 15clause returns the top 15 most semantically similar articles.
This semantic search can find relevant articles even if they don't contain the exact words used in the query. It understands the context and meaning of the search query and matches it with semantically similar content.
Performing Hybrid Search Using Pgai and Cohere Rerank
Hybrid search combines the strengths of both keyword and semantic searches and then uses Cohere's Rerank model to improve the relevance of the results further. This approach can provide more accurate and contextually relevant results than either method alone.
Here's how to perform a hybrid search with reranking:
Let's break down this query:
full_text_search: Performs a keyword search using PostgreSQL's full-text search capabilities.vector_query: Creates an embedding for our search query using Cohere's Embed model.vector_search: Performs a semantic search using the query embedding.combined_results: Combines the results from both keyword and semantic searches.reranked_results: Uses Cohere's Rerank model to reorder the combined results based on relevance to the query.- The final
SELECTstatement extracts and formats the reranked results.
This hybrid approach offers several advantages:
- It captures both exact keyword matches and semantically similar content.
- The reranking step helps to prioritize the most relevant results.
- It can handle cases where either keyword or semantic search alone might miss relevant articles.
To use this query effectively:
- Adjust the
to_tsqueryparameters to match your specific keyword search needs. - Modify the natural language query in both the
cohere_embedandcohere_rerankfunctions to match your search intent. - Experiment with the
LIMITvalues and the_top_nparameter to balance between recall and precision.
Remember, while this approach can provide highly relevant results, it does involve multiple API calls to Cohere (for embedding and reranking), which may impact performance for large result sets or high-volume applications.
This hybrid search method demonstrates the power of combining traditional database search techniques with advanced AI models, all within your PostgreSQL database using pgai.
Get Started With Cohere and Pgai Today
The integration of Cohere’s Command, Embed, and Rerank model into pgai marks a significant milestone in our vision to help PostgreSQL evolve into an AI database. By bringing these state-of-the-art language models directly into your database environment, you can unlock new levels of efficiency, intelligence, and innovation in your projects.
Pgai is open source under the PostgreSQL License and is available for you to use in your AI projects today. You can find installation instructions on the pgai GitHub repository. You can also access pgai on any database service on Timescale’s cloud PostgreSQL platform. If you’re new to Timescale, you can get started with a free cloud PostgreSQL database here.
Pgai is an effort to enrich the PostgreSQL ecosystem for AI. If you’d like to help, here’s how you can get involved:
- Got questions about using Cohere models in pgai? Join the Postgres for AI Discord, a community of developers building AI applications with PostgreSQL. Share what you’re working on, and help or get helped by a community of peers.
- Share the news with your friends and colleagues: Share our posts about pgai on X/Twitter, LinkedIn, and Threads. We promise to RT back.
- Submit issues and feature requests: We encourage you to submit issues and feature requests for functionality you’d like to see, bugs you find, and suggestions you think would improve pgai. Head over to the pgai GitHub repo to share your ideas.
- Make a contribution: We welcome community contributions for pgai. Pgai is written in Python and PL/Python. Let us know which models you want to see supported, particularly for open-source embedding and generation models. See the pgai GitHub for instructions to contribute.
- Offer the pgai extension on your PostgreSQL cloud: Pgai is an open-source project under the PostgreSQL License. We encourage you to offer pgai on your managed PostgreSQL database-as-a-service platform and can even help you spread the word. Get in touch via our Contact Us form and mention pgai to discuss further.
We're excited to see what you'll build with PostgreSQL and pgai!





